Masataro Asai and Alex Fukunaga
The University of Tokyo
12min
No details, read the paper! This is a pitch!
Made by guicho2.71828 (Masataro Asai)
1 Generic AI agent architechture

I first talk about the generic AI agent architecture.
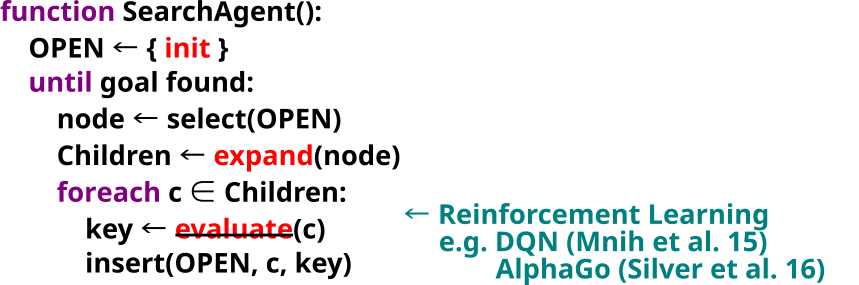
A search agent first inserts the initial node into the open list.
then until the goal is found, it selects a node from the open list, and expand the node to obtain the children. Then for each child, it evaluates the child and store it in the open list with the result of evaluation.
This agent structure is very generic, so it applies not only to the classical best-first search agent but also the greedy agent, which includes Reinforcement Learning agent.
Now let's think about which part of this generic architecture has been successfully automated by the deep learning so that it does not require the manual feature engineering.
It turns out, Reinforcement Learning only solves the evaluation part. However, there are more parts that are not yet addressed by reinforcement learning.
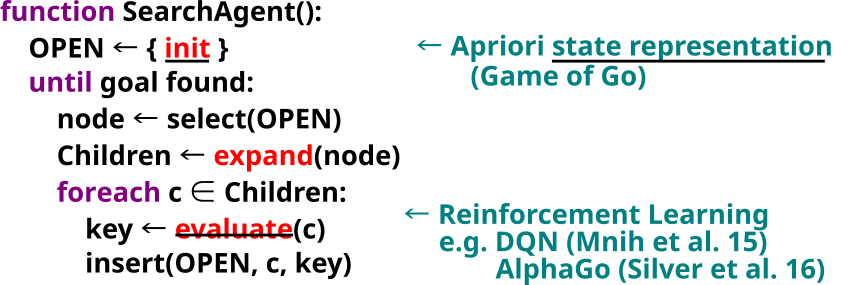
First, State representation. The famous AlphaGo, which uses an evaluation function trained by reinforcement learning, assumes that the state representation is given apriori.
Second, state transition rules. This is also typically assumed to be given apriori. In Alphago or AlphaZero, the game rules of Go or Chess are hard coded by human. Also, in DQN which operates on Atari Environment, the system has access to the simulator.
It is precisely these parts that we address in this presentation.
1.1 Generic AI agent architechture

1.2 Generic AI agent architechture

1.3 Generic AI agent architechture
1.4 Generic AI agent architechture
1.5 Generic AI agent architechture
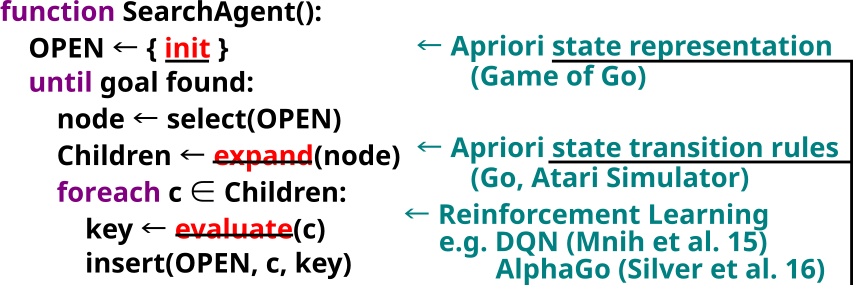
The scope of our paper ↑
2 Classical Planning: typically with a PDDL (symbolic) model
Modern planners solve an 8-puzzle optimally << 0.1sec
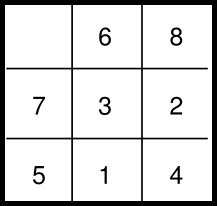 Initial State
Initial State
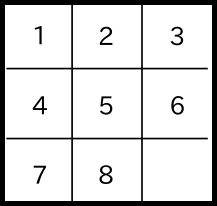 Goal State
Goal State

(empty x0 y0) (is panel6 x1 y0) (up y0 y1) (down y1 y0)...
(:action slide-up ... :precondition (and (empty ?x ?y-old) ...) :effects (and (not (empty ?x ?y-old))...))
3 They cannot solve an Image-based 8-puzzle

BECAUSE
WE
DO
NOT
HAVE
A
PDDL
MODEL!
Impractical in many environments:
unknown and no human is available
e.g. autonomous space exploration!
4 We must automate 2 processes:

→
(:action slide-up ... :precondition (and (empty ?x ?y-old) ...) :effects (and (not (empty ?x ?y-old))...))
1. Symbol Grounding:
Symbols = identifiable entities in PDDL
Types Examples Objects panel7, x0, y0 … Predicates (empty ?x ?y) Propositions p28 = (empty x0 y0) Actions (slide-up panel7 x0 y1)
2. Action Model Acquisition (AMA):
Describe the transitions with symbols.
When Empty(x, yold) ∧ … ;
Then ¬Empty(x,yold) ∧ …
- A Long-Standing Problem…
5 Latent-Space Planner (Latplan)
5.1 Task: Solving an Imaged-Based 8-puzzle without any Prior Explicit Knowledge
System is not given any labels/symbols : e.g. "9 tiles", "moving"
Given only raw, unsegmented images = unstructured
No notion of motion
5.2 Task: Solving ANY Imaged-Based task
→ Domain-independent Image-based Classical Planner
Tower of Hanoi

Lights-Out

5.3 Inputs
The system is given 2 types of input:
- Training Input
- Planning Input
5.4 Input1: Training Input – Image Pairs
Agent performed some action to the before-state, resulting in the after state
5.5 Input1: Training Input – Image Pairs
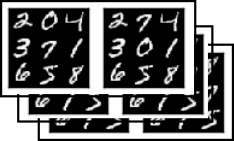
Randomly sampled transitions
as noisy image pairs
- No state descriptions (unlike AlphaGo)
- No expert traces (unlike AlphaGo)
- No rewards (unlike DRL in general)
No access to the simulator (unlike DQN+Atari)
→ cannot ask for more examples
No action symbols
(e.g. ↑↓←→Fire in Atari, grids in Go)
→ unlike any previous work to our knowledge,
Image pairs are unlabelled ground actions
ALL previous Acion Modelling systems require symbolic/near-symbolic state/action inputs.
(Konidaris et al. 2014, 2015), ARMS (Yang et al. 07), LOCM (Cresswell et al. 09), (Argall et al. 09), (Mourao et al. 12), Framer (Lindsay et al. 17)
DQN (Mnih et al. '15), AlphaGo (Silver et al. '16)
5.6 Input2: Planning Input

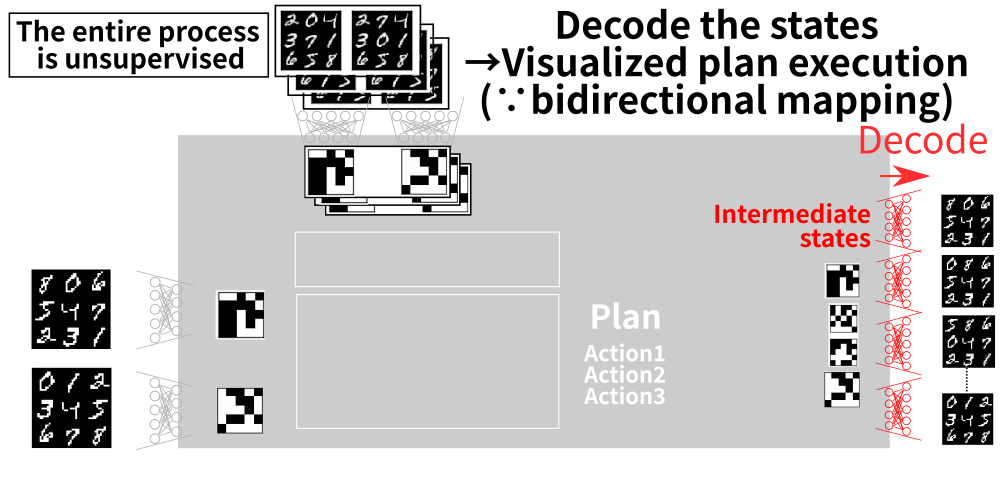
5.7 Output: Visualized Plan
5.8 Output: Visualized Plan
6 Latent-Space Planner (LatPlan) architechture
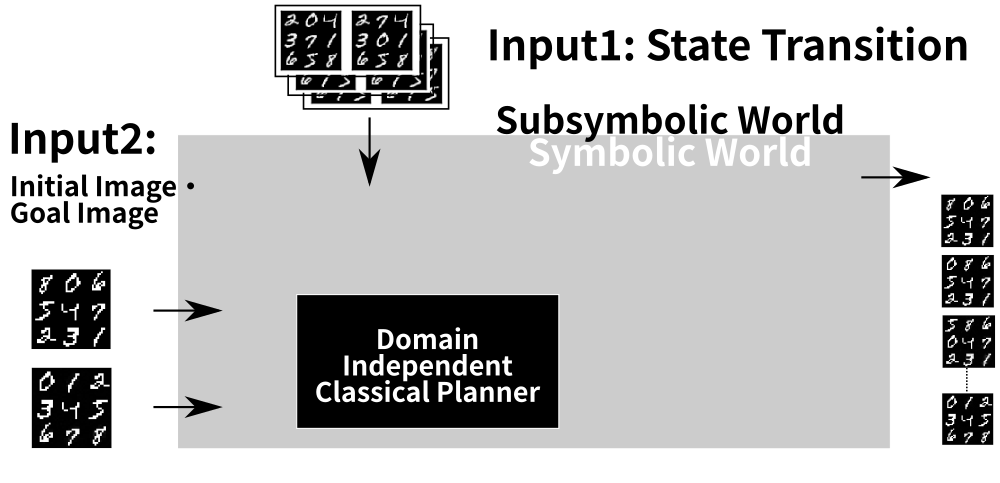
We must bridge the gap between these two worlds!
7 Step 1: Propositional Symbol Grounding
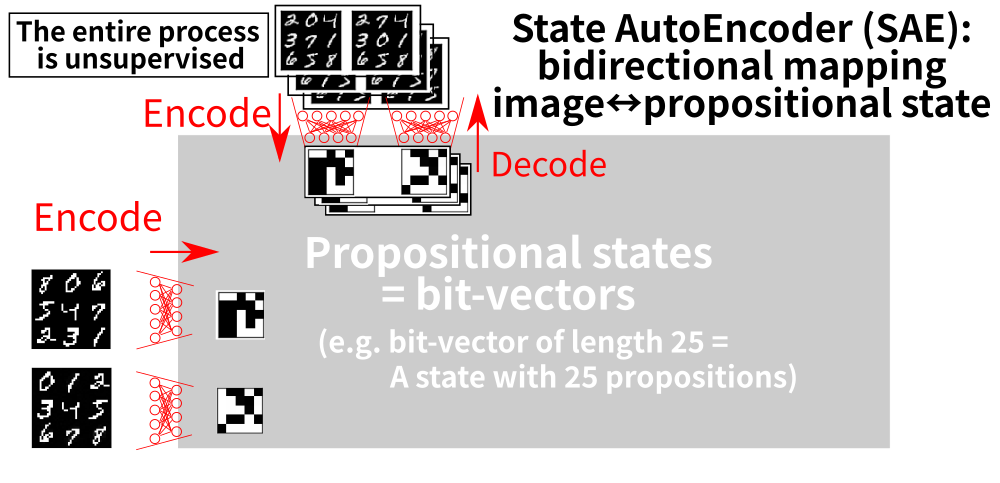
8 Step 2: Action Model Acquisition (AMA)
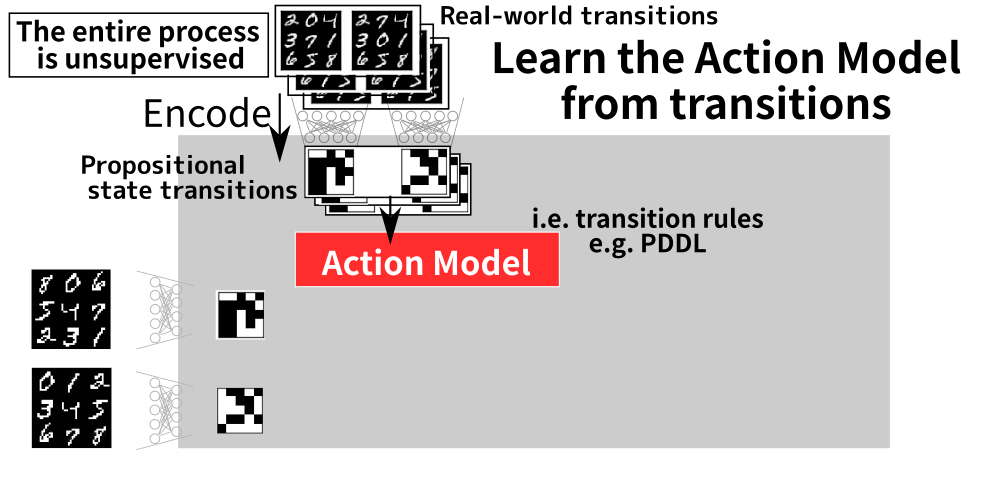
9 Step 3: Solve the Symbolic Planning Problem
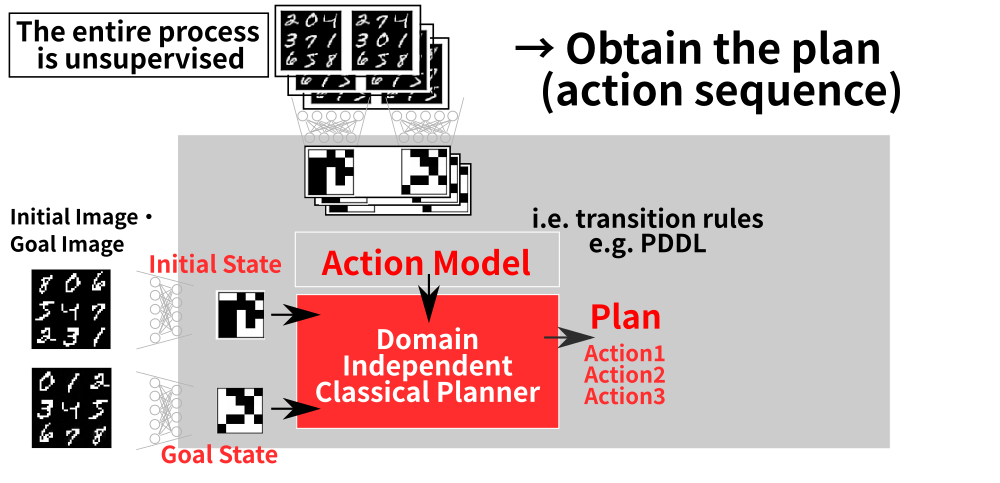
10 Step 4: Executing the Symbolic Plan
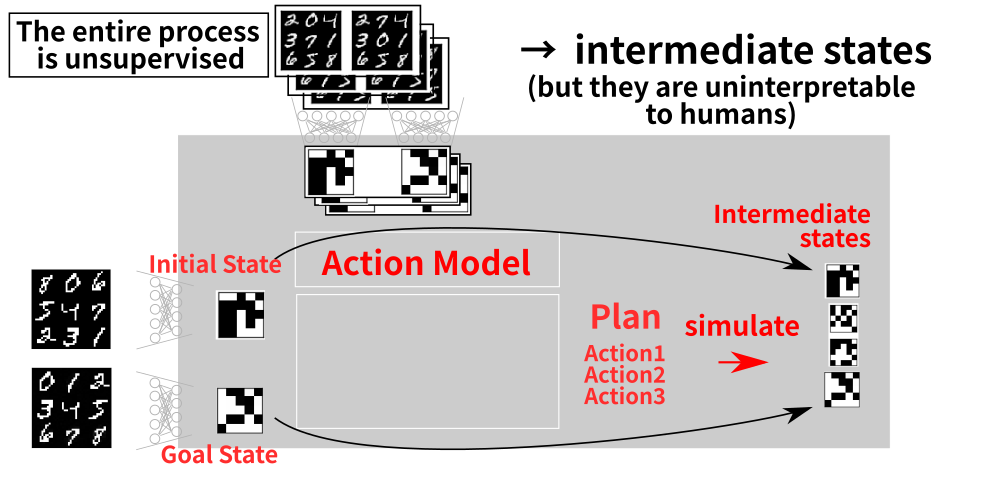
11 Step 5: Obtaining the Visualization
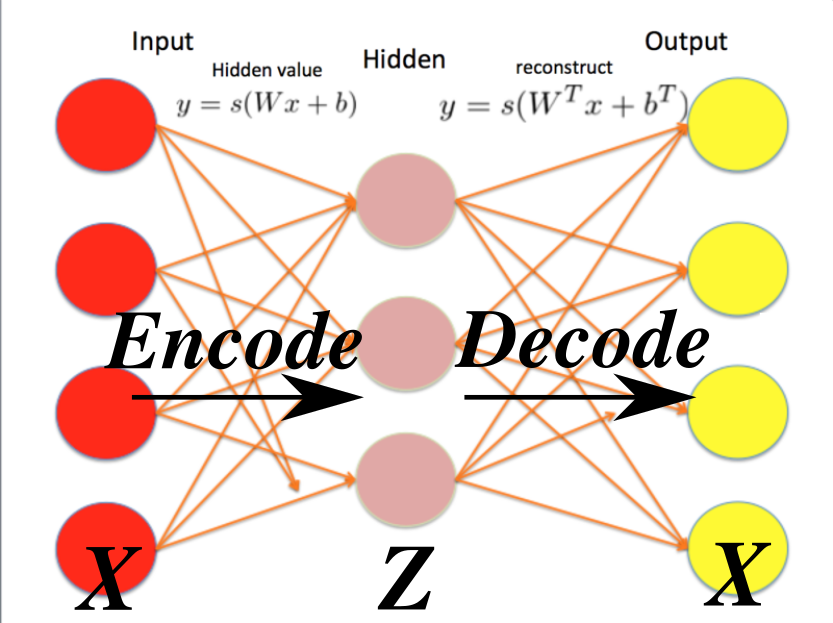
12 SAE ∈ AutoEncoder (AE): Unsupervised Learning for NN
Target Function: Identity $x=f(x)$
- Encode $x\;$to a latent vector $z$
- Decode $z\;$back to the input $x$
- Training: Minimize $|x - f(x)|\;$ (reconstruction loss)
adding a label: Latent vector
→ However, ✘ Latent vector Z is real-valued
INCOMPATIBLE with propositional reasoning
13 Solution: SAE as a Gumbel-Softmax VAE (Jang, Gu, ICLR2017)
Additional optimization penalty which enforces $Z \sim \textbf{Categorical}$:
→ $z\;$converges to a 1-hot vector e.g. $\langle 0,0,1,0 \rangle$.
Example: Represent an MNIST image with 30 variables of 8 categories.
Key idea: These categorical variables are directly usable
as the source of propositional models
In particular, 2 categories → propositional variables (true/false)
14 State Autoencoder (before training)

15 State Autoencoder (after training)

16 -
Q: Does the SAE (neural network) produce
sound propositions for reasoning?
AMA1 : an oracular Action Model Acquisition (AMA) method
w/o generalization.
- 1. Encode all image transitions in the environment
2. For each transition, perform the following conversion explicitly:
0011 → 0101 ;; encoded bit vectors of a transition ↓ ;; one action per transition (:action action-0011-0101 ;; before-state is embedded directly :precondition (and (b0-false) (b1-false) (b2-true) (b3-true)) ;; effect = state diff :effect (and (not (b1-false)) (b1-true) (not (b2-true)) (b2-false)))
- 3. Planning with Fast Downward (Helmert 08), A* (optimal solution)
16.1 8-puzzle with MNIST tiles (MNIST 8-puzzle)
8-puzzle using digits from MNIST database

→ 31 step optimal plan
(See paper for other domains with noisy inputs)
17 SAE propositions feasible! Now what?
○ SAE is practical.
Trained with 20k out of 360k state examples. (8-puzzle)
✗ AMA1 is impractical.
AMA1 requires all valid transitions in the real world
✗ Therefore SAE + AMA1 is impractical.
→ SAE + AMA2, a novel neural architecture
which learns from few examples
18 AMA2 Overview

18.1 Action Auto Encoder
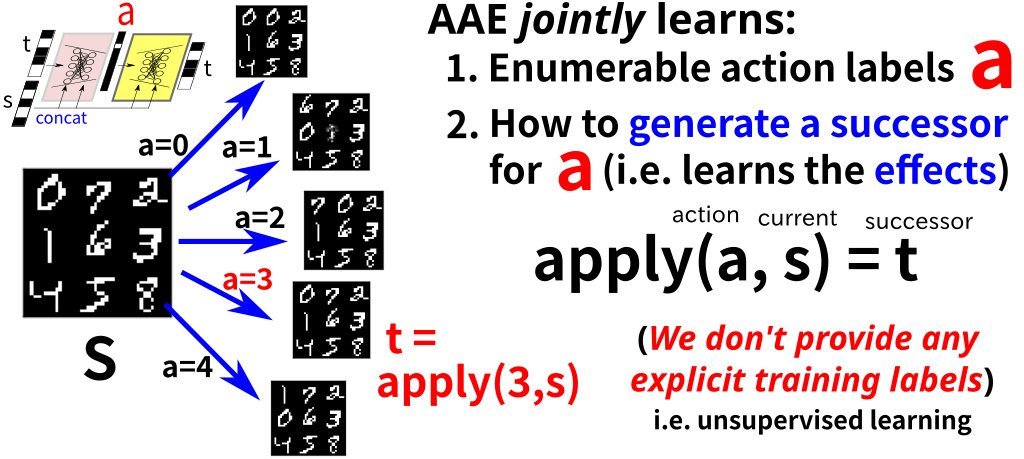
18.2 Action Auto Encoder → Incorrect Transitions
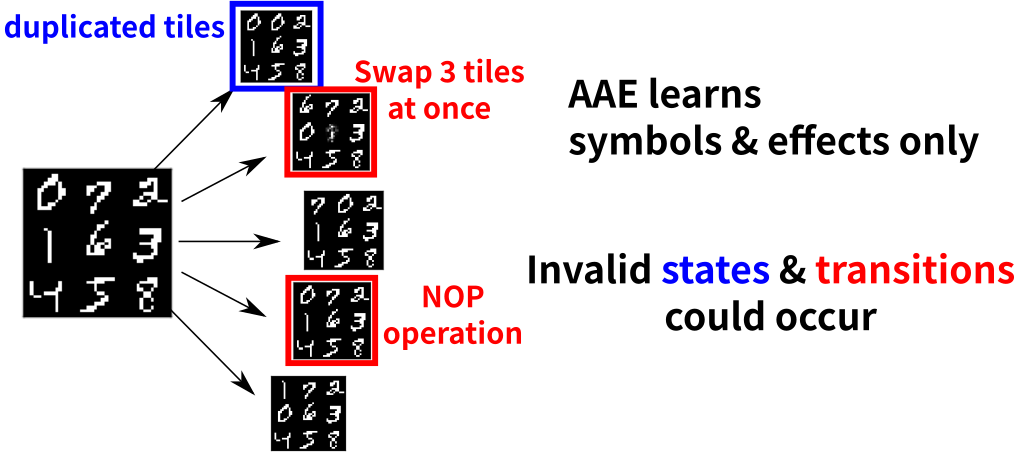
18.3 Action Discriminator → Prunes the Incorrect

18.4 Action Discriminator → Prunes the Incorrect
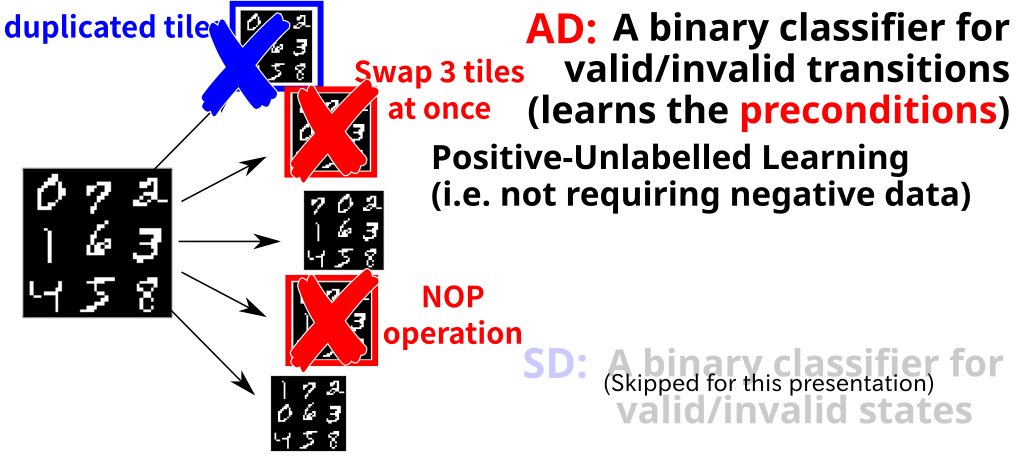
Elkan, Noto 08
18.5 Action Discriminator → Prunes the Incorrect

Elkan, Noto 08
18.6 AMA2 Overview

I completely skip the description of AAE and AD
please read the paper
19 AMA2 Experiments
Is it feasibile to do planning with AAE and AD?
Easy instances: Majority of instances are solved
Harder instances: Still many instances are solved
| / | < | > | < | > | ||
|---|---|---|---|---|---|---|
| step | 7 | 7 | 7 | 14 | 14 | 14 |
| noise | std | G | s/p | std | G | s/p |
| MNIST | 72 | 64 | 64 | 6 | 4 | 3 |
| Mandrill | 100 | 100 | 100 | 9 | 14 | 14 |
| Spider | 94 | 99 | 98 | 29 | 36 | 38 |
| LightsOut | 100 | 99 | 100 | 59 | 60 | 51 |
| Twisted LO | 96 | 65 | 98 | 75 | 68 | 72 |







19.1 AMA2 Experiments
Is it feasibile to do planning with AAE and AD?
Easy instances: Majority of instances are solved
Harder instances: Some instances are solved
| / | < | > | < | > | ||
|---|---|---|---|---|---|---|
| step | 7 | 7 | 7 | 14 | 14 | 14 |
| noise | std | G | s/p | std | G | s/p |
| MNIST | 72 | 64 | 64 | 6 | 4 | 3 |
| Mandrill | 100 | 100 | 100 | 9 | 14 | 14 |
| Spider | 94 | 99 | 98 | 29 | 36 | 38 |
| LightsOut | 100 | 99 | 100 | 59 | 60 | 51 |
| Twisted LO | 96 | 65 | 98 | 75 | 68 | 72 |
Action Discriminators achieved reasonable accuracy
the type-1 / type-2 error in %
| type1 | type2 | |
|---|---|---|
| MNIST | 1.55 | 6.15 |
| Mandrill | 1.10 | 2.93 |
| Spider | 1.22 | 4.97 |
| L. Out | 0.03 | 1.64 |
| Twisted | 0.02 | 1.82 |
| Hanoi | 0.25 | 3.79 |
20 Conclusion : Latplan
The first completely automated system
Unstructured images → A symbolic planning model
from scratch (no human symbols, structured data)
State AutoEncoder(SAE) : real-world states ↔ propositional states
Action AutoEncoder(AAE) : transitions ↔ action labels, effects
Action Discriminator(AD) : transition → bool with PU-Learning
Solved two of the major grounding problems
Types of symbols Handled by Latplan? Propositional symbols Yes Action symbols Yes Object symbols No Predicate symbols No
20.1 Future Work (Input format)
LatPlan is an architecture : Any system with SAE is an implementation
Different SAE → reason about different types of raw data
Autoencoders for text, audio [Li 2015, Deng 2010]
Latplan + Dialogue System:
Transition rule "This is an apple, this is a pen → oh, ApplePen"
1000 steps of natural language reasoning with logic, not by reflex
↑ Because classical planning can handle long sequences
"A hierarchical neural autoencoder for paragraphs and documents." (2015)
"Binary coding of speech spectrograms using a deep auto-encoder." (2010)
20.2 Future Work (Extended planning formalism)
- Latplan assumes nothing about the environment machinery (grids, movable tiles…)
- Latplan assumes fully-observable, deterministic domains
- Next step: Extending Latplan to MDP, POMDP
- Gumbel-Softmax layer → just a Softmax layer? (probability)
- $AO^*$, $LAO^*$algorithms for optimal planning under uncertainty
20.3 Future Work (Propositional → First-order)
SAE can generate propositional symbols (state $s = \{q,r\ldots\}$)
- 1st-order logic (predicate $p(a,b)$)
- We need object recognition from images (parameters $a,b$)
- SAE with networks for object recognition (e.g. R-CNN) should achieve this
20.4 Future Work (Knowledge extraction)
AMA2 (AAE/AD) is a neural network, thus precondition/effects are in a blackbox
Hinders deriving heuristic functions
Knowledge extraction by Konidaris et al.('14,'15), δ-ILP (Deepmind) ?
21 AMA1 Appendix
Using the Remaining Time (Discussion)
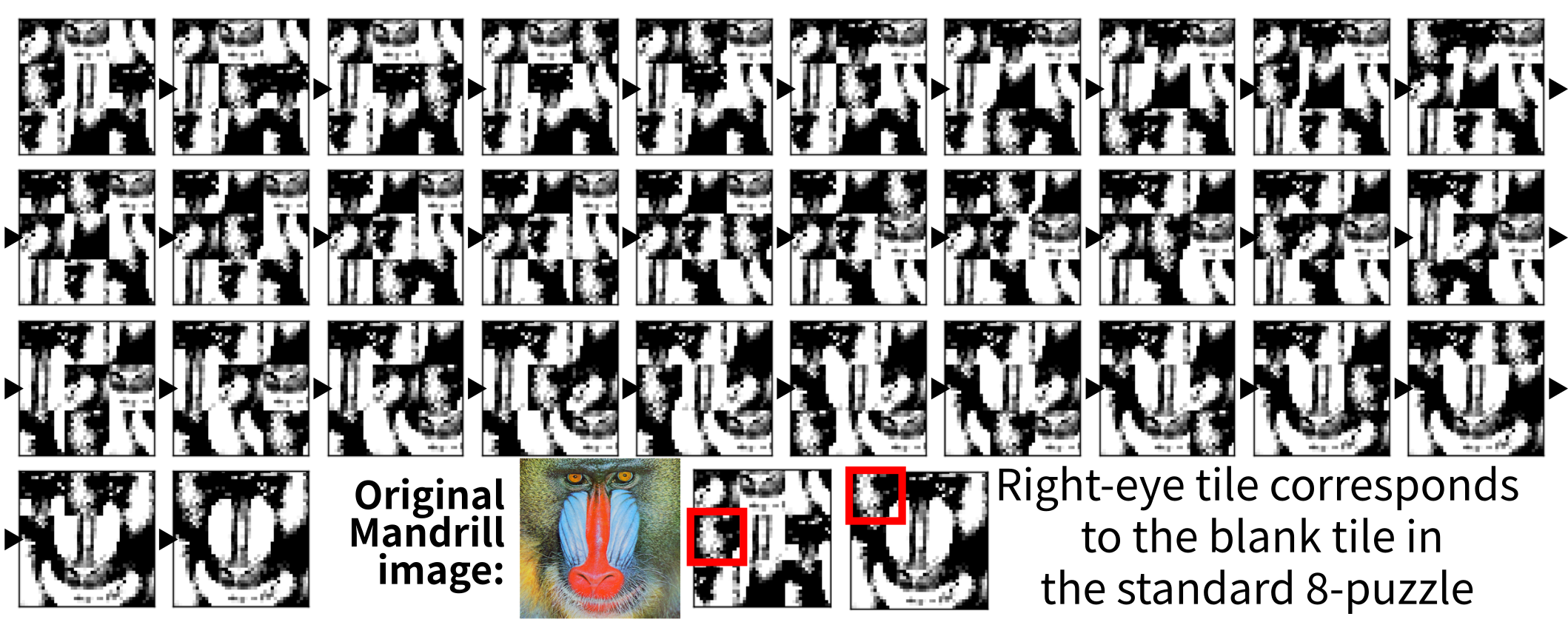
21.1 Results with photographic, unseparated tiles (Mandrill 8-puzzle)
MNIST 8-puzzle has cleanly separated objects -> This domain does not.
21.2 Results with photographic, unseparated tiles (Mandrill 8-puzzle)
Notice that latplan has no idea that this is an 8-puzzle; They are entirely different from the system's point of view
(We skip other domains)
21.3 Results with photographic, unseparated tiles (Spider 8-puzzle)
Notice that latplan has no idea that this is an 8-puzzle; MNIST, Mandrill, Spider are entirely different from the system's point of view
21.4 Tower of Hanoi (3 disks, 4 disks)
Completely different puzzle problems can be solved by the same system

→ Optimal Solution (7 steps,15 steps)
21.5 Lights Out
Does not assume "objects" are static (objects may disappear)
→ Optimal Solution
21.6 Twisted Lights Out
Does not assume grid-like structures
→ Optimal Solution
21.7 Handling the Noisy Input
SAE implementation uses a denoising layer (Denoising AE)
→ Benefit from existing DL methods immediately
→ Improved speed, robustness, accuracy
21.8 Konidaris et. al (2014, 2015):
Structured input (e.g. light switch, x/y-distance) ↔ unstructured image
33 variables ↔ 42x42 = 1764 variables (pixels)
Inputs are highly entangled; no straightforward representation exists
Action Symbols (move, interact):
modes of transitions are already segmented by human
Just converting Semi-MDP model to a PDDL model.
Could be used for extracting PDDL from AAE/AD
21.9 NNs for solving combinatorial tasks:
TSP (Hopfield and Tank 1985)
Neurosolver for ToH (Bieszczad and Kuchar 2015)
The input/output are symbolic.
21.10 Other Work Combining Symbolic Search and NNs
Embedded NNs inside a search to provide the search control knowledge
(i.e. node evaluation function)
Sliding-tile puzzle and Rubik’s Cube (Arfaee et al. 2011)
Classical planning (Satzger and Kramer 2013)
The game of Go (AlphaGo, Silver et al. 2016)
21.11 Deep Reinforcement Learning (DRL) (Mnih et al. 2015, DQN)
DQN assumes predetermined action symbols (↑↓←→+ buttons).
DQN relies on simulators. ↔ Latplan reverse-engineers a simulator.
DQN does not work when it does not know what action is even possible!
21.12 Other Interesting Systems
SCAN system (deepmind)
Maps continuous latent vector and human-provided symbolic vector
- They are missing points because they don't think about what symbols are for
- They are for efficient, automated reasoning!
- Floats are not efficient, humans can't be involved
δ-ILP (Inductive Logic Programming)
- ILP robust to noise
- Extracting rules from AAE/AD to form a PDDL?
21.13 Why bother the off-the-shelf planner? Shouldn't the blind search do?
Domain-independent lowerbounds work, SURPRISINGLY!
This is NOT a trivial finding!
lower-bounds are…
- taylored for man-made domains
- assumes the domain has a structure
Blind search even sometimes outperform sophisticated methods on man-made instances (Edelkamp 12)
- lb works → more difficult problems can be solved (future work)
Number of states expanded, mean(stdev.)
| domain | N | Dijkstra | A*+PDB |
|---|---|---|---|
| MNIST | 13 | 210k(50k) | 97k (53k) |
| Mandrill | 12 | 176k(13k) | 112k (57k) |
| Spider | 13 | 275k(65k) | 58k (30k) |
| Hanoi | 30 | 20.7(29.7) | 12.6 (22.0) |
| LightsOut | 16 | 433(610.4) | 130 (164) |
| Twisted | 16 | 398(683.1) | 29.3 (62.4) |
N : number of instances.
All results are AMA1 (produce PDDL)
21.14 Why Gumbel-Softmax is necessary?
- Alternative 1: Use a normal NN and round the encoder output?
- ✘ The decoder is not trained with 0/1 value
- Alternative 2: Include the round operation in a NN?
- ✘ Rounding is non-differentiable / Backpropagation impossible
21.15 Why not individual pixels? Why DL?
Systems based on individual pixels lack generalization
Noise / variations can make the data entirely different

- must acquire the generalized features
- = a nonlinear function that recognize the entanglements between multiple pixels
22 AMA2 Appendix
22.1 Successor Function
AAE: enumerates, AD: filtering the invalid.
\begin{align*} Succ(s) &= \{t = apply(a,s) \; | \; a \in \{0\ldots 127\},\\ & \qquad \land AD(s,t) \geq 0.5 \} \end{align*}Now we can run $A^*$with goal-count heuristics
with action symbols and propositional states
22.2 Why action symbols are necessary?
Planners typically perform a forward search (Dijkstra, $A^*$)
Without Action Symbols, successor generation becomes challenging
SAE with $|z|=36 \text{bit}$
→ Generate $2^{36}$potential successors, then filter the invalid
- With action symbols, (e.g. up, down, left, right)
- → We can enumerate the candidates in constant time.
22.3 Training Input lacks action symbols
Should identify the number of schemas from what is un/affected
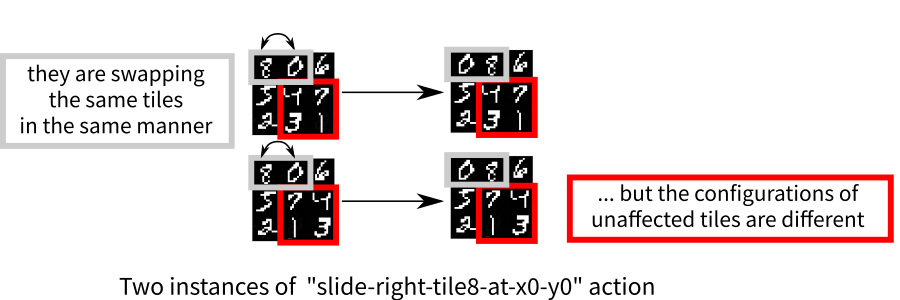
22.4 Precondition/Effect learning is not trivial
Case 1: Linear Space
- We do not need an action label; it is linear anyways
- Then, AMA ≡ prediction task ($\approx$scene prediction in video)
- We can train a neural network $a(s) = t\;$by minimizing $|t-a(s)|$
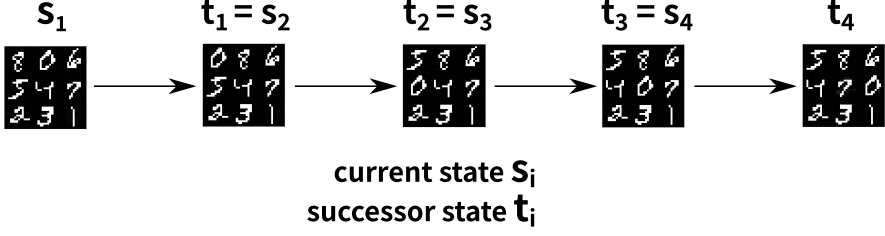
22.5 Precondition/Effect learning is not trivial
Case 2: Graphs
- Multiple action labels
Varying number of successors
for each state
- Therefore we cannot train $a(s) = t\;$for each $a$ because we don't know which (s,t) belongs to which $a$.

- Correct Question: What is the right function to learn?
22.6 Action AutoEncoder
What is the right function to learn?
$a(s) = t$
We cannot train this
$a$is a variable!
$apply(a,s) = t$
Transition is a mapping
action $a → $ successor $t$
conditioned by
the current state $s$
The right function to learn!
23 Basic Appendix for ML people
23.1 Learning vs Planning
Main differences: Purposes and the abstraction layer
Machine Learning, Neural Networks
for Recognition, Reflex
Subsymbolic Input (continuous)
Images, Audio, unstructured text:
Soft Intelligence:
Reflex Agent, Immediate actions
Pavlov's dog : bell → drool
Autonomous Driving : Pedestrian → Stop.
Machine Translation : Sentence → Sentence
Eval. Function for Go : board → win-rate
☺ Quick 1-to-1 mapping
☹ Simple tasks
Deliberation, Search
for Planning, Game, Theorem Proving
Symbolic Input/Output
Logic, objects, induction rules
Hard Intelligence by Logic:
Multi-step strategies
Rescue Robot : actions → help the surviver
Theorem Proving : theorems → QED
Compiler : x86 instructions
Game of Go : stones → Win
☺ Ordering constraint + complex tasks
- AlphaGo = Subsymbolic (DLNN eval. function) + Symbolic (MCTS)
23.2 Human-Competitive Systems
AlphaGo = Subsymbolic (NN eval. func) + Symbolic (MCTS)
- However, domain-specific – specialized in Go, "Grids" / "Stones" are known
- Huge expert trace DB — Not applicable when data are scarse (e.g. space exploration)
Is supervised learning necessary for human?
True intelligence should search / collect data by itself
DQN = Subsymbolic (DLNN) + Reinforcement Learning (DLNN)
Domain-independent Atari Game solver (Invader, Packman…), however:
- RL Acting: Greedily follow the learned policy → no deliberation!
- You can survive most Atari games by reflex
23.3 Latplan Advantages
Perception based on DLNN
— Robust systems augmented by the latest DL tech
Decision Making based on Classical Planning
— Better Theoretical Guarantee than Reinforcement Learning
Completeness (Finds solution whenever possible), Solution Optimality
— Decision Making Independent from Learning
Unsupervised (No data required), Explainable (Search by logic)
23.4 When Latplan returns a wrong solution?
Machine learning may contain errors (convergence only on $t\rightarrow \infty$, not on real time)
- Images → Fraud symbols/model/graph
Optimal path on a fraud graph or graph disconnected
A* completeness, soundness, optimality (admissible heuristics)
- Fraud visualized plan (noisy) / no plan found
LatPlan may make wrong observations but no wrong decisions
BTW, "correctness" is defined by error prone observations by humans anyways …
(completeness, optimality) → better reliablility than Reinforcement Learning
23.5 Reinforcement Learning
Both perception and decision making depend on training
- When the learned policy is wrong,
- the solution could be suboptimal
- It could even fail to find solutions (incomplete agent)
… AlphaGo was unprepared for Lee Sedol’s Move 78 because it didn’t think that a human would ever play it.
Cade Metz. "In Two Moves, that Redifined the Future." Wired, 2016
RL may make wrong decisions.
23.6 Why symbols?
Symbols are strong abstraction mechanisms becasue
- Meanings do not matter
You do not have to understand it: Does a symbol $X$mean an apple or a car?
Logical reasoning can be performed by mechanical application of rules
Domain-independent planning : mystery vs nomystery
Logistic domains where symbol names are mangled (truck → shark)
- Composable
A latent vector is a conjunction (and)
Heuristic functions use modus ponens to derive guidance
24 Neural-Symbolic AI.
